DataOps: Where and How To Start (Stat)
- By Ethan Peck, Tamr
- April 20, 2021

You’re responsible for managing data as an asset for your organization. From our first post in this “Accelerating DataOps” series, you’ve been reminded that DataOps is a continuous process and not a single event. Second, that perpetually clean, healthy, and trustworthy data for your data pipelines is in the critical path to success.
You have critical data that you want to pipeline to solve a business problem or seize a business opportunity. But you won’t know how “bad” the problem or how rich the opportunity is until you: (1) get some actually “good” data and (2) make it fit for consumption (e.g., for operational improvement or analytics).
Unfortunately, the path to clean, curated data is rarely straightforward. You’re almost guaranteed your data will be a mess because of decades of amassing data silos, inconsistent data management, and messy data exacerbated by freewheeling updates and duplicate-record creation.
Further, the organizational resources to “fix” the data (i.e., people, processes, and technology) are often hard to identify and cost-justify. There are legacy technologies that need to be either embraced or replaced. There are legacy processes that haven’t evolved to take advantage of new skills, knowledge, or measurement capabilities. The cold truth is that there is no single packaged solution to your problem but rather a collection of best-of-breed solutions from which to choose.
But where to start?
The answer: take a triage approach.
Much like how ER doctors must prioritize which patients to treat first in an emergency, you need to determine what to prioritize and where to martial your initial efforts with DataOps. Which of my entities is in dire need of help? Which is in pretty good shape, or can wait? Which is hopeless? What organizational resources will I need, and by when, to be effective? What technologies need to be involved, and which do we have ready to deploy versus the need to acquire?
Here’s the process, from a high level:
Diagnose the Data Problem
To start, you need to stay agile and get a handle on all of your “symptoms” before you can “cure” the data with a complete DataOps pipeline. Therefore, plan to do a small spike project first.
Start by building a data pipeline for a single data entity. Whichever entity you choose, make it an important entity to a business problem or opportunity and thus likely to be a good sample “patient” that will turn around a quick return on your investment. For example, a common entity is a Customer Account, widely used across business organizations (although not always known by that exact name), frequently changing, and with data stored in multiple systems (e.g., ERP systems, Salesforce, and other CRMs).
Your team will need to include subject matter experts, people chartered with the curation of Customer Accounts within their business unit, and technical resources capable of building your data pipelines and setting up required technological solutions.
Apply the Right Therapies
Next, build a DataOps pipeline through it, going through all of the usual steps, using your most advanced therapies.
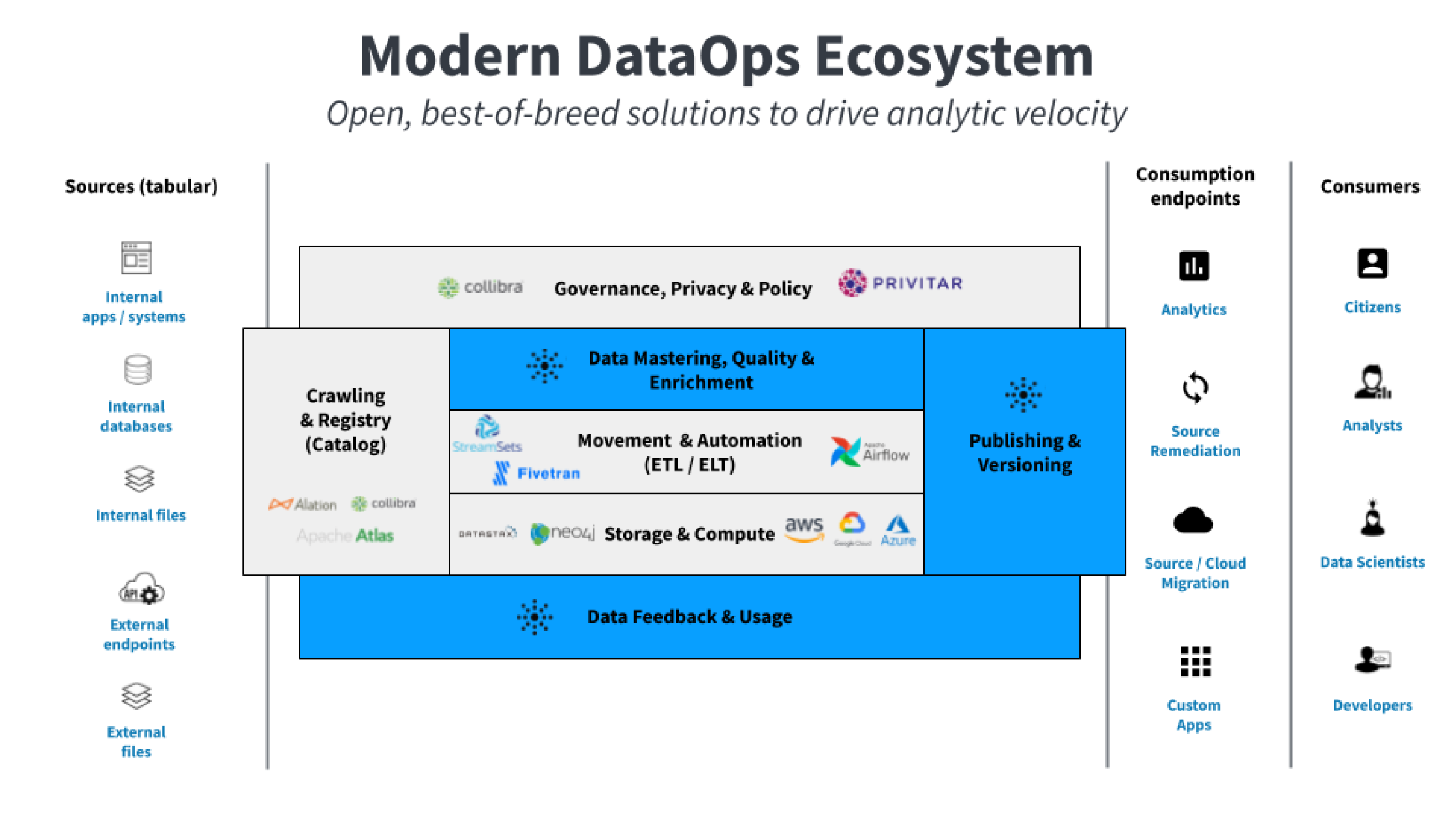
Cataloging (crawling and registry services) can help find and identify your data sources. From this exercise, you’ll discover how consumption-ready your data is: how distant it may be, how messy its source systems, what software is involved, and so on. Next, go deeper to learn the status of the underlying data sources at an intimate level. For example, how many languages is your data in? Is the data standardized or in 15 different formats? Is it curated, and if so, what is the process of that curation?
You’ll now be able to prioritize all the related data sources to get a complete picture of them and their health (individually and holistically). This will enable you to focus the right amount of attention on each data source according to priority.
Data mastering, quality, and enrichment will help you get the data ready for production use. Modern schema mapping, low-latency matching, and data mastering techniques can help speed this part of the process. It is important to keep in mind that your data is constantly changing and evolving. Thus any solution here must remain iterative and easy to update over time. There is no such thing as a one-time cleanup of a data entity.
Discharge a Stable Patient
Finally, you’re ready to publish your data to its consumers (such as data scientists or analysts) for use in generating actionable business insights. Because you used the correct and most modern therapies, the data goes home with a clean bill of health.
For now, anyway. It’s important to remember that this process was a temporary fix to a single data entity at this point. Just like in a real ER visit, the patient needs some follow-up appointments to heal the disease or wound fully.
Congratulations: Your triage worked!
By identifying the real problem and its severity upfront and mustering the right resources to solve it, you’ve gotten your data to a better state of health and usability.
More importantly: You now have a model that can be applied to future “patients.” If done successfully, the ROI from the spike project can often fund the next pipeline project and so on, creating a self-funding model for a culture of healthy data in perpetuity.
You didn’t “boil the ocean” by starting with an over-ambitious, top-down project for data transformation. You made it out of the Emergency Room, alive and well, with a prescription for healthy, analytics-ready data for DataOps that can be reapplied.
The original article by Ethan Peck, head of data and technical operations at Tamr, is here.
The views and opinions expressed in this article are those of the author and do not necessarily reflect those of CDOTrends. Image credit: iStockphoto/BrianAJackson; Chart: Tamr









