Quickly Building Agile Data Pipelines Using Modern Data Mastering
- By Ethan Peck
- August 25, 2021

Here’s a guide to the data mastering component of the DataOps landscape.
First Rule: Don’t Boil the Ocean.
Don’t waste time on a grand, top-down plan to transform all your data overnight (or years) for pipelining. And absolutely do not spend a lot of time figuring out a complete architecture for the pipeline: a general idea is good enough. Too much time spent creating a grand architecture to host your pipelines is just as bad as spending too much time on a grand plan to build those pipelines.
Next, choose one data entity that’s important to your business to create a spike project. Plan to take it through the pipeline process (see diagram below). Use the resources available to you in your infrastructure, your organization, and where necessary through the emerging modern DataOps ecosystem. Triage the process such that diagnosis, treatment, and healing of the data can happen in parallel as much as possible.
A spike project will familiarize you with the pipelining processes you need to master an entity, a sense of what your current tooling set is, potential tooling needs and knowledge gaps, and how/where to prioritize. Keep in mind that you’ll not only be triaging your data but also triaging your organization’s ability to handle a DataOps workflow during your project.
By getting through a spike project successfully, you’ll be able to scale the method to other entities in the future. An added benefit is that you can often fund additional projects with the ROI from the previous projects, creating a self-funded DataOps machine.
Pro tip: During your spike project, there will be a natural gravitational pull towards waterfall techniques. Resist this! Your spike project is the leader of your modern data mastering and pipelining revolution.
Let’s walk through an example of a modern data mastering project using the Customer Account entity (you may call it by another name).
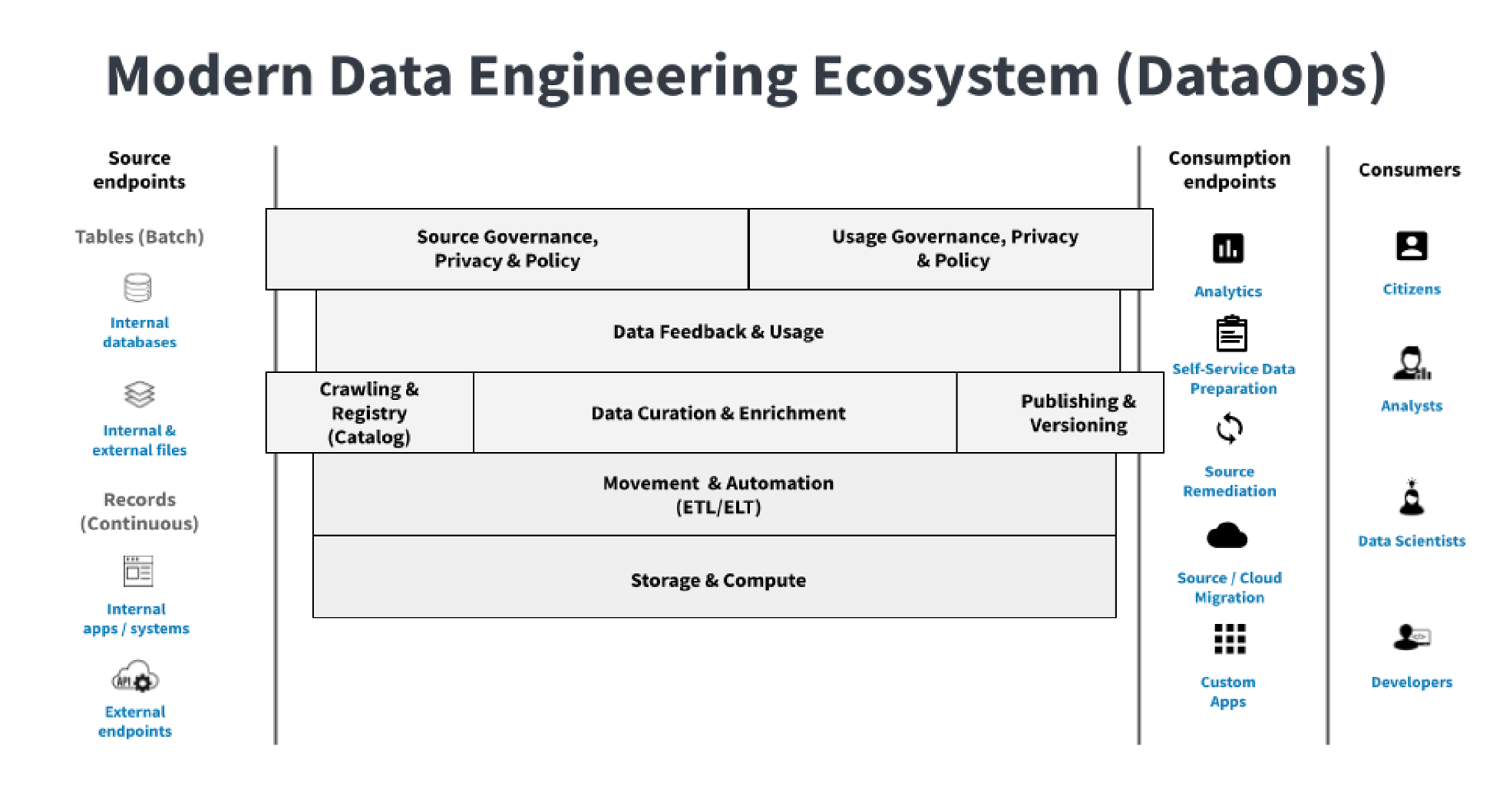
Find, Tag, and Clean Your Data
First question: Where’s my data? This is often one of the harder and more time-consuming questions to answer.
In a best case scenario, you already have a data catalog. You may even have an automated data crawler that constantly finds new data sources and registers them in your data catalog.
However, it’s more likely you don’t have a catalog to lean on. This means you will need to spend time finding your data in source tools or a data lake if you are lucky. Do not worry about this. You don’t need to build a whole data catalog now for your spike project. However, the amount of pain you go through during this step will help you to prioritize building a data catalog in the future.
While manually searching for the data (since there is no data catalog), you can multi-task by initiating a search for the resources you’ll need to perform the rest of the spike. Namely, these are subject matter experts (SMEs) familiar with the data to be curated and a data curator for the entity being created and curated.
Even if you have a catalog, you’ll need these resources. This takes time. Therefore, starting the search early, even while looking for your data, makes sense.
Data Cleansing
Extract-transform-load (ETL) tools will handle most data cleansing and quality assurance, but really dirty data may require more intensive data work, including using specialty tools. Regardless, whichever ETL tool you choose for your architecture, make sure it embraces the agile philosophy. Look for tools that can automate and speed up the ETL process with modern technologies like machine learning, cloud, and APIs, making the process as intelligent, flexible, responsive, and self-sustaining as possible.
Machine learning can automate data cleansing while the cloud can automate flexible provisioning of compute resources, eliminating the lag times in traditional waterfall methods and getting cleansed data into pipelines sooner. Some tools can do data cleansing, but they don’t specialize in it.
Depending on your budget, consider taking a best-of-breed approach and selecting a tool specifically designed for flexible, iterative, ML-powered data cleansing. However, don’t give up entirely on data cleansing if you don’t have the budget for it. Instead, try to use what you already have to achieve good-enough levels for now.
Again, stay agile. If you play this right, the spike will justify the budget for improving the entire pipeline later.
Embrace Data Enrichment
Next up would normally be creating a master data model for your entity. However, a vital DataOps best practice is data enrichment, an iterative step between data discovery and mastering.
Most previous efforts in mastering data have reflected human thought, also known as “tribal knowledge” (extracted from individuals’ heads and now captured idiosyncratically in your data.) Machine learning can expedite mastering a lot by natively extracting tribal knowledge in building your new data model. This is done by discovering patterns as a data expert starts marking data records as the same or not. In the absence of ML, this is proxied through the rules in more traditional rules-based mastering systems. However, this approach by definition limits utilization to only those fields that the experts are aware they’re using and not necessarily all of the information contained with the records being compared.
It’s also highly likely that some of your data is not native to your data model.
For example, a data expert finds two company records that list the same city but slightly different street addresses. In going into Google Maps, the expert finds that the locations are actually two different entrances to one building. That small lookup isn’t native to your current data. If you need to do the lookup using a human, the computer isn’t going to figure that out for you. Thus, you’ll need to add some geospatial data to your entity mastering model for the system to come to the same conclusion the expert did. Or maybe you need to look something up in another enterprise system, one not previously considered, to figure out if the two addresses are the same.
This data is known as enrichment data. It resides in another system and thus needs to be added to enrich your original data source. When enrichment data is combined with source system data, the resulting data model can now include a complete picture of the data being mastered as seen by a subject matter expert. Enrichment data makes sure you have enough data for effective mastering.
In keeping with good DataOps practices, do not take a waterfall approach with your data enrichment. Instead, enrich your data as you master, iterating between enriching and mastering until you reach an output that meets your needs.
More data is not always the solution. More model training is not always the solution. More rules are not always the solution. Instead, measure your progress and choose to enrich more or train more when progress stagnates. Stay agile!
Mastering Data Models
In DataOps, mastering is an iterative process and thus should be as agile as possible. Use bottom-up, human-guided ML-aided mastering (my shameless plug to promote Tamr). The mastering results will be more flexible with data variability, and model tuning iterations will shrink with time. If you’re using traditional, top-down rules-based mastering, however, you’ll likely make one set of rules, create a model, find that it’s not enough data, and then have to create a new set of rules, which involves going back and looking at all previous rules.
In DataOps, machine learning shortens mastering cycles; conversely, rules-driven mastering cycles tend to get longer. Faster results equate to faster feedback and iteration, one of the tenets of DataOps.
Machine learning, flexible cloud resourcing, and APIs for easy integrations and automation are some of the most powerful enabling technologies behind DataOps in general and in mastering and enrichment in particular. The combination allows you to stay agile and get results fast.
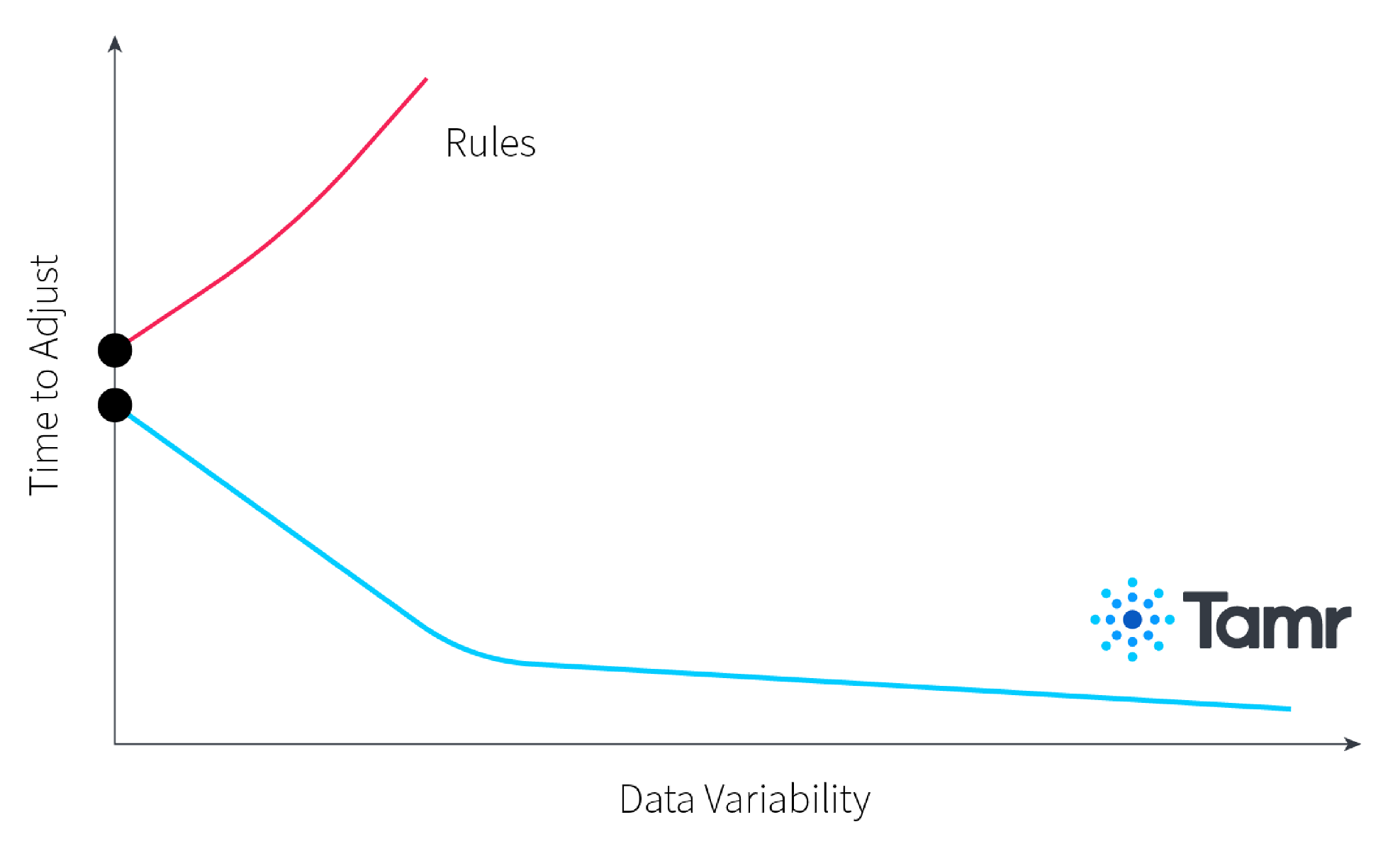
Mathematically speaking, using ML-driven mastering techniques will scale linearly with data variability. The rate of change in data variability generally decreases as more data is added as it becomes harder and harder to find data that is entirely different from any other data sources you have already placed in the system. Meanwhile, rules-based mastering approaches will scale exponentially with data variability since your new rules need to coexist with the rules already created, which means that you are in a race between generating rules and increasing data variability. This is a race you are likely to lose, so it’s strongly recommended to use ML-driven mastering techniques when possible.
An added benefit of committing to ML-driven mastering is that your models are flexible. Data drift is a fact of life. Your attributes may change, or an upstream data entry mechanism will modernize. The good news is that ML models can be quickly retrained and corrected for better performance without too much additional effort. Quick iterations that retrain the model account for minimal cost in maintaining your mastering pipeline. Time to fix is usually measured in hours and days, not weeks and months. Rules, on the other hand, are inflexible and brittle. When a rule starts to fail, it fails hard. Rules are also hard to unwind as rules often stack; cleaning rules up piece by piece can take an incredible amount of time and resources. This is more reason to stick to ML-driven pipelines whenever possible, especially when working on the first project.
Cloud can dramatically cut the time to spin up compute resources for testing data pipelines, to redeploy and scale those resources (you can change the size of a virtual machine at the push of a button), and to move data quickly from Point A to Point B. Being able to master large amounts of data in the cloud will be critical for succeeding in digital transformation.
APIs are widely embraced by modern DataOps tools, making it easy to connect data sources to data sinks, tools to tools, and data entities to consuming systems and users. Almost all ETL tools can leverage APIs, so choosing tools for your DataOps pipeline with well-constructed APIs is crucial in staying modular and agile.
ML, cloud resourcing, and API-driven tools can dramatically speed up your project timetable.
Publishing Data to Consumers
The output of the data cleansing, enrichment, and data mastering process is curated, published, clean, actionable, and trustworthy data for business and data consumers.
If you’ve done your spike project correctly, publishing should be more of a data engineering and people experiment than a technology-heavy effort. It involves putting the mastered data into a query-able system of your choice. Query systems can range from your data catalog or data lake to a traditional relational database.
This makes it easy to connect up systems that your data consumers are using to view the data, such as systems like Salesforce (for business users) or an operational data store (for consumption by raw data sources or objects as enrichment data) or analytics tools like BigQuery for your data scientists. You may require another iteration cycle to fine-tune your master data model for consumers, while some users (like data scientists) may just take the data and run with it from there.
Regardless, if you use modern DataOps tools and processes, you’ll get your actionable data into the hands of consuming systems and people quickly and cleanly.
The End Game: Self-Managing Pipelines
Your spike project is done. You now know what it takes for one entity. Now, what will it take to do another one of these? How can you improve the process? What tools did you have? Which tools do you wish you had?
The spike project may have been challenging (and even painful), but it’s over. And the ROI should typically be greater than the cost of the process to pipeline the single entity. Now you can utilize some of that ROI to fuel your next project and make it just a little bit easier. Just as the spike project involved interactions between steps to optimize results, so too will you iterate on whole projects, making them better and easier to complete the more of them you do.
If you leveraged agile DataOps technologies, you now likely just need a few people to maintain the pipeline. It will run on its own for the most part. A curator will look in occasionally to keep an eye on it for data or schema drift, updating the ML model, or adding a new rule to account for any such drift. But these steps will involve much less effort than the original pipeline because you now have the process nailed down.
This article was adapted from the original by Ethan Peck, formerly head of data and technical operations at Tamr found here.
The views and opinions expressed in this article are those of the author and do not necessarily reflect those of CDOTrends. Image credit: iStockphoto/Anterovium; Graphics and charts: Tamr









