Your Data Wants a GenAI Makeover
- By Mathews Thomas, Utpal Mangla and Dinesh Verma, IBM
- March 04, 2024

The data considerations for generative AI are similar and, in another sense, very different than those for traditional AI (i.e., AI/ML technologies preceding generative AI). In traditional AI, the primary goal of data was to train the AI model. In the age of generative AI, large foundation models come pre-trained over a large volume of data. However, the data the model may be using may not be typical or representative of the business data within one’s enterprise.
Except for the few companies trying to put out their foundation models, the primary goal of data collection and curation for an enterprise would be to customize one of the available foundation models for their specific task. This customization would take one of three forms – (i) fine-tuning the existing model, (ii) using the data in one of the private data usage patterns, such as Retrieval Augmented Generation (RAG), where prompt engineering may occur, or (iii) use the data post-inference to guard against model hallucinations.
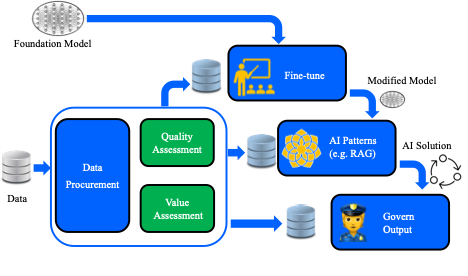
As data is collected for each of these three tasks, two key measures of data need to be taken into account: The first is the quality of information in the data (QoI), and the second is the value of information (VoI) in the data. QoI considerations include assessments of how good the data is (e.g., resolution of collected images or percentage of malformed data). In contrast, VoI considerations include how relevant the data is to solving the business task using generative AI.
Data quality depends on many factors, such as the source of the data provider, the errors that may have been introduced in the data during the collection process, or the bias that may have been introduced in the data during the collection process. A quality assessment approach must be followed to ensure the highest quality data is available. To assess the value of information to the task, a data selection process to select the most appropriate data for the AI task must be used.
Many commercial tools assist in data maintenance and governance across multiple vendors. The various tools for data governance need to be used as part of the solution, along with a robust methodology and business workflow to ensure that all aspects of data quality and data value are handled in the manner most suitable for the business problem that AI is applying to.
In summary, it is essential to consider how you will customize your foundation model. This should include careful consideration of how this customization will be done with data governance. An approach that integrates customization with governance will ensure you have laid down the core foundation to ensure your data is integrated successfully with your GenAI strategy.
The views and opinions expressed in this article are those of the author and do not necessarily reflect those of CDOTrends. Image credit: iStockphoto/Supatman









Mathews Thomas, Utpal Mangla and Dinesh Verma, IBM
Mathews Thomas is a distinguished engineer at IBM. He has held various research, software development, consulting, technical sales, and marketing positions. He currently focuses on Telco and Media & Entertainment and has prior experience in Retail, Industrial and E&U. His technical focus areas include GenAI/AI/Analytics, analytics, hybrid cloud, blockchain, 5G and edge computing.
Utpal Mangla is a general manager responsible for Telco Industry & EDGE Clouds in IBM. Before that, he was the vice president, senior partner and global leader of TME Industry’s Centre of Competency. He led the 'Innovation Practice' focusing on AI, 5G EDGE, Hybrid Cloud and Blockchain technologies for clients worldwide. Under Utpal's leadership, IBM recently achieved the mission of scaling to make "Watson AI Impact 1.5 Billion Consumers” and creating "Industry Blockchain platforms". Utpal is a Master inventor at the forefront of making Hybrid Cloud and 5G/EDGE real for enterprises globally.
Dinesh Verma is an experienced researcher, business leader, innovator and software developer at IBM. He is an IEEE Fellow, IBM Fellow, AAIA Fellow and Fellow of the U.K. Royal Academy of Engineering. He has authored 11 books, 200+ technical papers and 200+ U.S. patents and led multiple multi-national, multi-organizational research programs for over 15 years. He contributed to several IBM products and service offerings with documented business impact exceeding USD4B+. At IBM, he has served in various roles, including CTO, strategist, chief scientist, and senior manager.