Simplifying Data And AI With a Data Lakehouse
- By Paul Mah
- February 08, 2023

Why do so many organizations find it difficult to leverage the power of data analytics and AI? According to Matei Zaharia, the cofounder and chief technologist at Databricks, the reason is not that data-related problems are intrinsically hard, but that the technology infrastructure that businesses build to manage their data is often more complicated than it needs to be.
For the uninitiated, Zaharia started the Apache Spark project during his PhD at UC Berkeley in 2009 before founding Databricks, and today is also an assistant professor of Computer Science at Stanford. He was in town at the STACK conference in November to share his insights about the future of data and the role of the data lakehouse.
The power of data
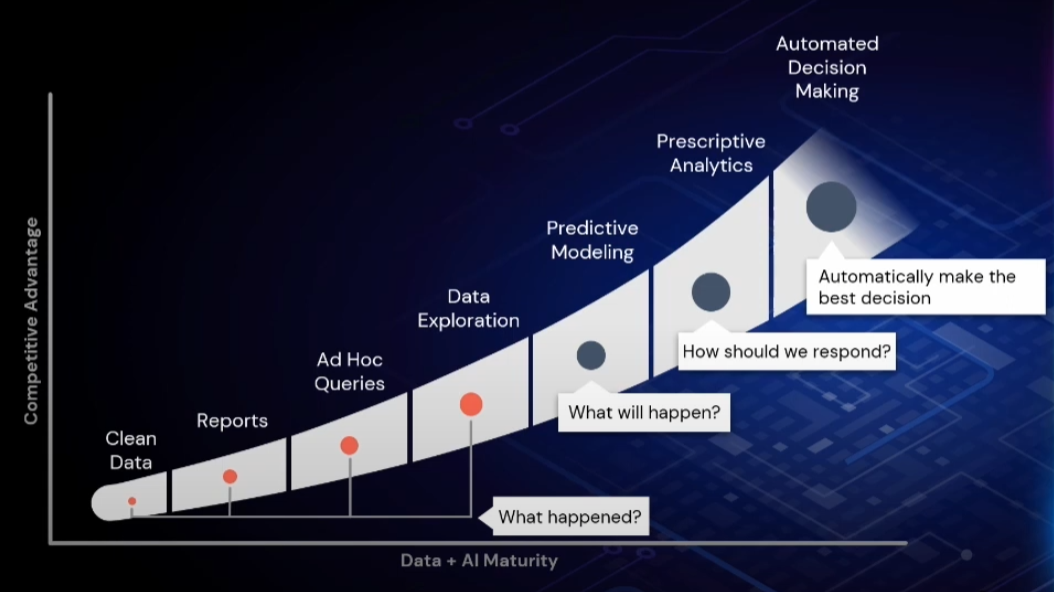
To illustrate the benefits of data, Zaharia started with a diagram to illustrate data and AI maturity against the competitive advantages that businesses can expect to gain.
“To get anything going with data and AI, you need to have clean data. And then you can do historical reports, ad hoc data exploration, and so on. So all of this stuff on the left side of the curve is to answer the question of what happened; it's looking in the past,” he explained.
However, the most successful businesses are those that have what it takes to move beyond the past: “The really exciting applications that are transforming organizations and industry are the ones that look more towards the future.”
Data is not just for tech companies, asserts Zaharia, and “fantastic use cases” of data and AI can be found in just about every sector.
He shared how Goldman Sachs and its use of AI to approve and underwrite credit card applications made through the iPhone took it practically overnight from zero to USD50 million in revenue for the Apple Credit Card. In the same vein, Walmart saved some USD100 million by using AI and data from across their suppliers and stores to optimize the supply chain during the pandemic, says Zaharia.
“Once you have a great data infrastructure in place, you can start to do predictive modelling and try to answer what will happen. You can start to do prescriptive analytics, what should we do, and you can even try to do automated decision making in the present – to have your application or your service do something right now as people interact with it.”
Harder than it needs to be
But why are so many organizations struggling with data? According to Zaharia, a big part of the problem could be attributed to the incompatible data platforms and infrastructure. And when data queries must span multiple disparate platforms, the result is far greater complexity even for rudimentary tasks.
“Most organisations still struggle to use data analytics and AI. A lot of the reason for this is not necessarily that these problems are intrinsically hard, but also that the technology infrastructure we've built for these is more complicated than it needs to be,” he explained.
Invariably, businesses are forced to copy data between systems, which jacks up the cost and results in disjointed, cumbersome data sets with high operational and management overheads.
“Something as simple as deleting all the records of one user is very hard to do safely on a data lake because those records could be in so many different files. You have to create a transaction just to update the files; if you go and edit the files one by one, then readers might see some inconsistent data. And if you crash, you need to recover your job,” said Zaharia.
The power of the data lakehouse
This is where lakehouse storage solutions such as Databrick’s Delta Lake come into the picture. It puts a metadata layer in front of the raw file storage to keep track of database tables and data files, including versioning.
“Client applications talk to this layer to access the data. With a simple design, the metadata layer can support features like multi-versioning, concurrency, ACID transactions, maintain indexes, keep metadata in sync, and quite a few other data management features,” he said.
Zaharia says there is no technical reason why world-class SQL performance cannot be obtained directly from the data lake using data lakehouse technology, pointing to how Databricks SQL achieved the world record on the official 100 terabyte TPC-DS benchmark in 2021 (we wrote about it here).
“We have done a whole bunch of comparisons of our photon engine against traditional data warehouses using their formats. It is extremely competitive both in execution time and price performance; it is often faster and cheaper by more than a factor of two than many of the best engines on the market.”
Simpler and faster
Indeed, the reason why data lakes are traditionally used only for niche data analytics and not for broader use across the enterprise is due to its lack of management, says Zaharia. This changes with the data lakehouse, however, and “quite a few companies” are now building query engines from the ground up to work with the data lakehouse, he said.
Coupled with its open data management architecture, it is no wonder why a data lakehouse paradigm is now catching on with improvements and features constantly being built. Ultimately, having an effective data platform is about more than just storage. “It helps a lot to have only a single copy of storage, and to have an interface that can be used for all the workloads.”
“Our goal with this is the design next-generation infrastructure for data and AI. And we think it has to be simple, open and multi-cloud to succeed. And we do think there's a lot of room to simplify the data stack and to bring ml streaming and data engineering much closer together and save people's time to focus on the actual business problems,” summed up Zaharia.
Paul Mah is the editor of DSAITrends. A former system administrator, programmer, and IT lecturer, he enjoys writing both code and prose. You can reach him at [email protected].
Image credit: iStockphoto/LuCaAr










Paul Mah
Paul Mah is the editor of DSAITrends, where he report on the latest developments in data science and AI. A former system administrator, programmer, and IT lecturer, he enjoys writing both code and prose.